Method
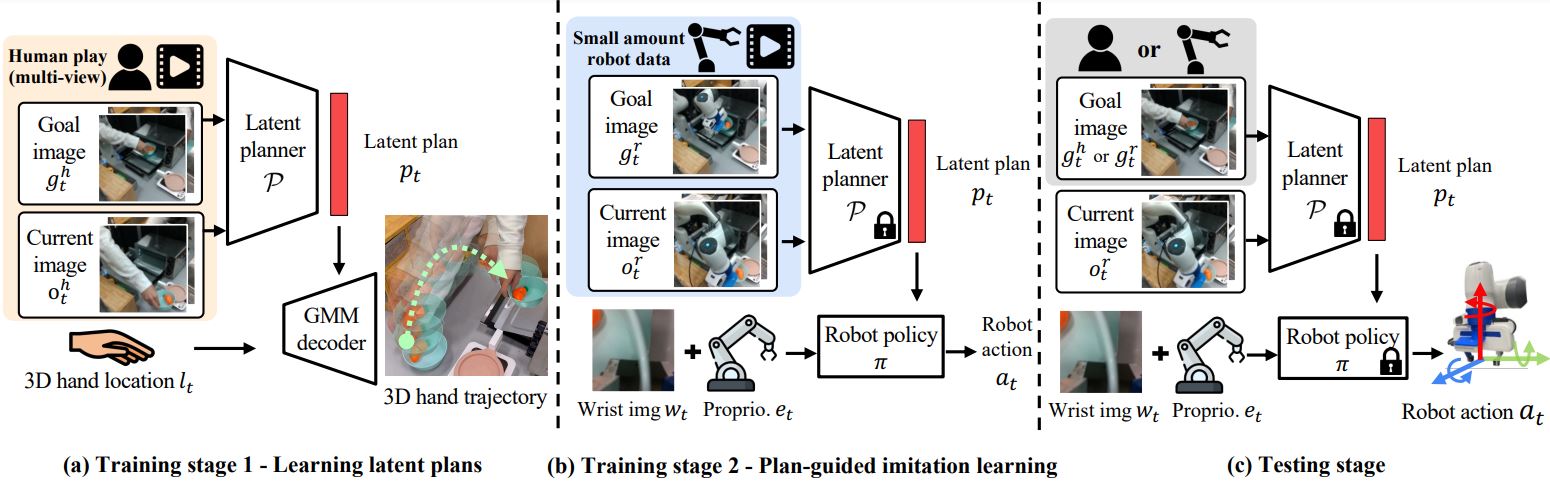
Overview of MimicPlay. (a) Training Stage 1: using cheap human play data to train a goal-conditioned trajectory generation model to build a latent plan space that contains high-level guidance for diverse task goals. (b) Training Stage 2: using a small amount of teleoperation data to train a low-level robot controller conditioned on the latent plans generated by the pre-trained (frozen) planner. (c) Testing: Given a single long-horizon task video prompt (either human motion video or robot teleoperation video), MimicPlay generates latent plans and guides the low-level controller to accomplish the task.